
Spring Batch AWS Series (III): Remote Partitioning
In this post we are going to implement our second step using remote partitioning strategy. The goal of this step is to calculate the next probable prime given a number.
Description
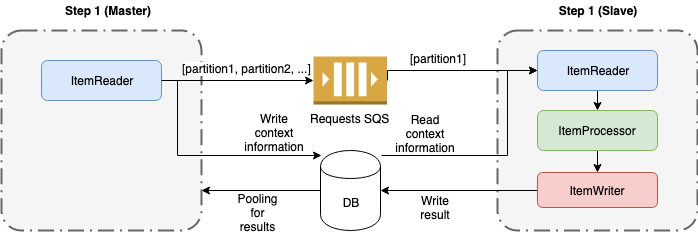
Remote Partition is similar to remote chunking because receives messages from a SQS queue but the response is not sent to other SQS queue. The context information is stored in database instead of message. The process is as follow:
- The master sends messages for each partition to SQS and store the information for the slave in the DB. Then start polling the DB for results.
- The slave reads the message from SQS, reads the associated information in DB and processes the work.
- The slave marks in DB as completed when finishes the work.
- When all the partitions are completed, the master continue to the next step.
Master project
The master project will store the partition info in the database and will send a message to the slaves by each partition. Meanwhile it will check in database if all the slaves have finished. We could configure a timeout for the case that some slave don’t response.
“Master => Slave” Integration Flow (Request outbounds)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Bean
public IntegrationFlow step2RequestIntegrationFlow() {
return IntegrationFlows.from(step2RequestMessageChannel())
.transform(stepExecutionRequestToJsonTransformer)
.handle(buildMessageHandler())
.get();
}
private MessageHandler buildMessageHandler() {
SqsMessageHandler sqsMessageHandler = new SqsMessageHandler(amazonSQSAsync);
sqsMessageHandler.setQueue(REQUEST_QUEUE_NAME);
return sqsMessageHandler;
}
- Read from
step2RequestMessageChannelchannel. In this channel theMessageChannelPartitionHandlerwill write the info about the partition. - The previous channel will receive a
StepExecutionRequestobject with all the necessary information for the slaves. In this step we’ll transform this object in Json using our own tranformStepExecutionRequestToJsonTransformer. - Send to SQS. This handler will send the previous message to SQS using
SqsMessageHandler - The master will check the database using the jobExplorer with the poll interval indicated. The max timeout for wait the slaves also can be specified. All this parameters can be setted in
MessageChannelPartitionHandler.
1
2
3
4
5
6
7
8
9
10
11
12
13
@Bean
public PartitionHandler buildPartitionHandler() {
MessageChannelPartitionHandler partitionHandler = new MessageChannelPartitionHandler();
partitionHandler.setGridSize(10);
partitionHandler.setStepName(STEP_NAME);
partitionHandler.setMessagingOperations(buildMessagingTemplate(step2RequestMessageChannel()));
partitionHandler.setJobExplorer(jobExplorer);
partitionHandler.setTimeout(30 * 60 * 1000); // 30 minutes
partitionHandler.setPollInterval(10000); // 10 seconds
return partitionHandler;
}
Slave project
“Slave => Master” Integration Flow
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
@Bean
public IntegrationFlow step2RequestIntegrationFlow() {
return IntegrationFlows.from(buildSqsMessageDrivenChannelAdapter())
.transform(jsonToStepExecutionRequestTransformer)
.handle(buildStepExecutionRequestHandler())
.channel("nullChannel")
.get();
}
private StepExecutionRequestHandler buildStepExecutionRequestHandler() {
StepExecutionRequestHandler stepExecutionRequestHandler = new StepExecutionRequestHandler();
stepExecutionRequestHandler.setStepLocator(beanFactoryStepLocator);
stepExecutionRequestHandler.setJobExplorer(jobExplorer);
return stepExecutionRequestHandler;
}
- Read from SQS messages using
SqsMessageDrivenChannelAdapterand send the json to the transformer. - Transform the received json in
StepExecutionRequestusingJsonToStepExecutionRequestTransformer - The
StepExecutionRequestHandlerwill get the step in database and execute the step for each partition. - With
nullChannelwill finish the integration flow.
In this case the slave will indicate in database when its work has been finished so it’s not necessary to use a response queue.
Results
This is a example logs for an execution with 10 partitions with random numbers.
1
2
3
4
5
6
7
8
9
10
The number received is 7829 and the next probable prime is 7841
The number received is 1615 and the next probable prime is 1619
The number received is 4846 and the next probable prime is 4861
The number received is 6523 and the next probable prime is 6529
The number received is 276 and the next probable prime is 277
The number received is 857 and the next probable prime is 859
The number received is 2066 and the next probable prime is 2069
The number received is 4364 and the next probable prime is 4373
The number received is 3493 and the next probable prime is 3499
The number received is 2535 and the next probable prime is 2539
How to run
- Run the docker-compose.yml file
docker-compose upTMPDIR=/private$TMPDIR docker-compose up(MAC users)
-
Create the queues if don’t exists
1
aws sqs create-queue --endpoint http://localhost:4576 --queue-name step2-request.fifo --attributes '{"FifoQueue": "true", "ContentBasedDeduplication":"true"}' -
Run one or more slaves using the main class
com.frandorado.springbatchawsintegrationslave.SpringBatchAwsIntegrationSlaveApplication - Run the master using the main application
com.frandorado.springbatchawsintegrationmaster.SpringBatchAwsIntegrationMasterApplication
References
[1] Link to the project in Github
[2] Spring Batch AWS Series (I): Introduction